14 Gaussian Mixture Model
14.2 Expectation-Maximization Algorithm
Expectation-Maximization(EM) 알고리즘은 확률을 optimize, maximize하는 데 많이 사용되며, hidden variable이 존재하는 상황에서 maximum likelihood를 구할 때 사용한다.
예를 들어, 어떤 함수를 최대화하고 싶다면 EM 알고리즘을 사용할 수 있다. (gradient ascend와 매우 유사)
다음 목적함수에서 maximum을 찾고 싶다고 하자. 2번과 3번 과정을 반복하며 최대값을 찾을 수 있다. (주의: local optimum에 해당)
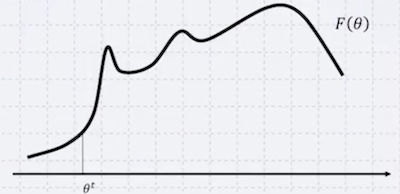 |
1. 임의의 point 선택 |
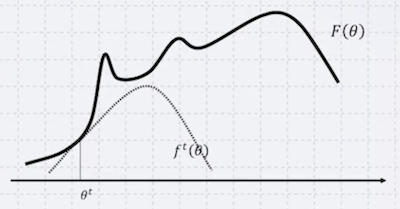 |
2. 세 조건을 만족하는 함수 생성 - 위로 볼록(convex upper) - for all - |
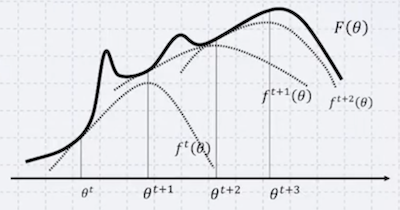 |
3. 를 maximize하는 선택 ( ) |
2번 풀이: 목적함수 F보다 항상 같거나 작은데, 에서의 값은 F와 같다.
14.3 Background: Jensen's Inequality
Jensen's Inequality는 위로 볼록한 함수(convex function)에서 성립하는 부등식이다.
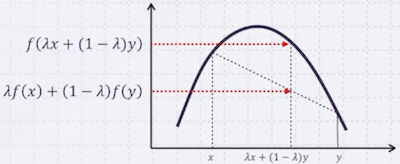
- 가 위로 볼록할 경우
이는 다음과 같이 일반화할 수 있다.
모두 합산했을 때 1이 되는 를 로 바꿔치면, 이를 확률로 해석할 수 있다.
의 평균은, 의 평균을 에 넣은 값보다 작거나 같다.
14.3.1 Logarithm and Jensen's Inequality
로그 함수 역시 위로 볼록한 함수이므로, Jensen's Inequality가 성립한다.
이때, 대신 양수인 함수 를 넣어도 성립한다.
14.3.2 Likelihood with Hidden Variable
앞서 유도한 수식을 바탕으로 likelihood를 계산해 보자.
바게트 잘라먹기 적용. ( : hidden variables )
위 수식에서 내가 random하게 고른 를 대입하면, 는 상수가 된다. (즉, 분수 부분이 1이 된다.)
식에 Jensen's Inequality를 적용하면 다음과 같다. (우변을 로 정의)
이제 를 상세하게 분석해 보자. ( 증명 )
결국 앞에서 말한 3가지 조건을 모두 만족한다.
14.4 Maximize Likelihood
이제 likelihood를 maximize하는 를 찾는 문제로 돌아가 보자.
EM Algorithm을 적용하면 다음과 같다.
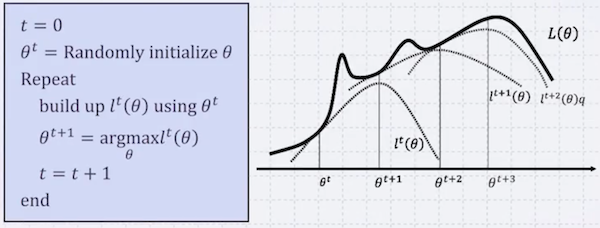
build up 부분을 Expectation step (E-step), argmax 부분을 Maximization step (M-step) 라고 지칭한다.
이때 식은 다음과 같이 정리할 수 있었다.
14.5 GMM by EM Algorithm
이제 실제 GMM에 어떻게 적용되는지 살펴보자.
-
주어진 데이터
-
Gaussian
-
Hidden
개의 Gaussian의 평균과 분산을 찾는 것이 목적이다. 이는 찾고 싶은 평균과 분산을
로 정의한 뒤, EM 알고리즘을 적용하면 된다.

최종적으로 Maximization step에서 다음 문제를 풀이하면 된다.
이는 조건을 만족할 때 argmax 해를 찾는 것으로, constrained optimization, SVM에서 본 문제와 유사하다.
위 식은 Lagrange multiplier를 통해 쉽게 풀이할 수 있다. 해의 형태는 다음과 같다.
Note: 는 E-step에서 계산한 값이다.