14 Gaussian Mixture Model
Gaussian Mixture Model(GMM)은 Unsupervised 기법 중 하나이며, Clustering의 확률적 접근 방식이다.
14.1 Gaussian Mixture Model
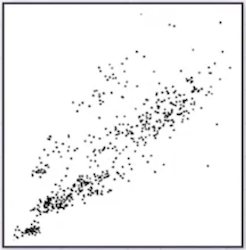
먼저 대표적인 클러스터링 기법인 k-means는 경계를 넘어가면 바로 다른 클러스터에 속하게 된다. 반면 GMM은 soft한 경계를 갖는데, 예를 들어 어떤 경계에 속할 확률을 0.3, 다른 경계에 속할 확률을 0.7으로 볼 수 있다.
| GMM | |
|---|---|
 |
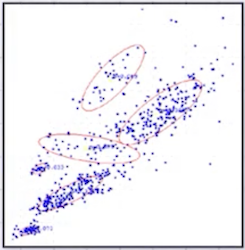 |
위 예시처럼 GMM은 cluster로 타원 형태를 갖는다. (k-means는 원 형태)
14.1.1 Mixture of Gaussians: Example 1
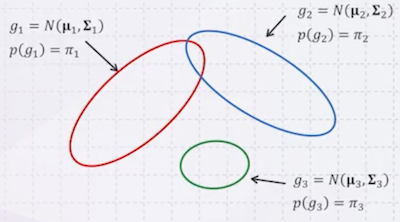
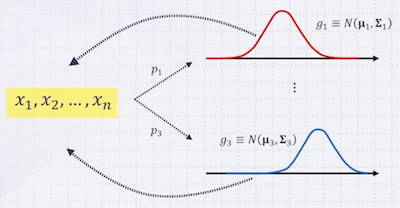
먼저 간단한 예시를 몇 가지 살펴볼 것이다. 다음은 data generation으로, 3개의 Gaussian distribution이 있다고 하자. (평균, 분산은 알려져 있음)
- 3가지 Gaussian 중 하나를 임의로 골라서 생성하는 과정을 회 반복 시 확률
: 각 Gaussian이 선택될 확률
 |
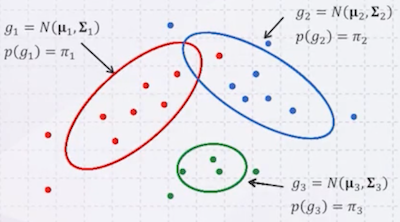 |
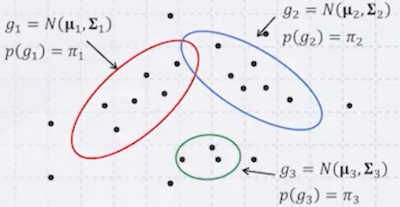
빨간색 점이 빨간 원을 벗어나 있지만, GMM은 soft한 경계를 갖기 때문에 얼마든지 가능하다.
14.1.2 Mixture of Gaussians: Example 2
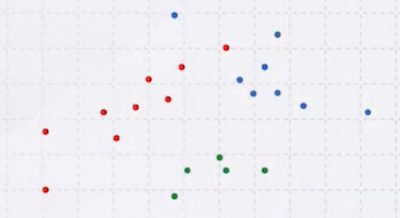
이번에는 3개의 Gaussian에서 생성한 데이터가 있지만, 각 Gaussian의 평균과 분산을 모른다고 가정하자.
또한, 각 점이 어떤 Gaussian에서 생성되었는지도 모른다.
이러한 문제는 상당히 풀기 매우 어렵기 때문에, 가정을 추가하여 생각할 것이다.
가정 1 가정 2
가정 1. 3개의 Gaussian의 평균과 분산을 알고 있다.
위 가정이 있다면, 각 점이 어떤 Gaussian에서 생성되었을 확률을 계산할 수 있다.
반면, 다음과 같은 가정도 가능하다.
가정 2. 각 점을 어떤 Gaussian에서 생성했는지 알고 있다.
이는 각 데이터를 바탕으로 각 Gaussian의 평균과 분산을 계산하면 된다.
Summary
를 안다면, 를 구할 수 있다.
= Gaussian의 평균, 분산과 initial probability를 알면, 각 점이 어떤 Gaussian에서 생성되었는지 알 수 있다.
를 안다면, 를 구할 수 있다.
= 각 점이 어떤 Gaussian에서 생성되었는지 알면, Gaussian의 평균, 분산을 알 수 있다.
14.1.3 Mixture of Gaussians: Example 3
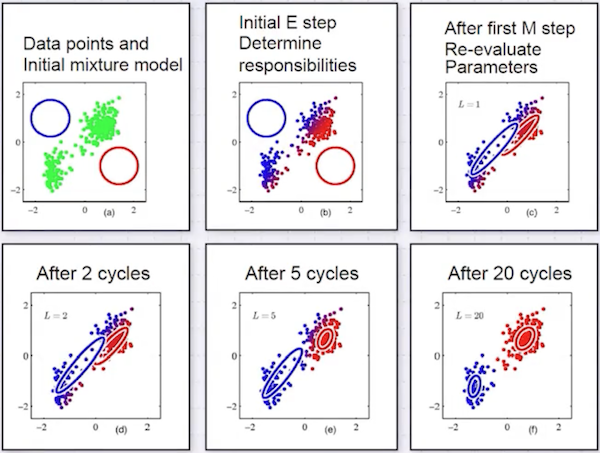
그렇다면 둘 다 모르는 상황에서는 어떻게 해야 할까? 이는 하나를 randomly initialize하는 방법으로 해결할 수 있다.
- 를 임의로 초기화
- 위 를 바탕으로, 추정
- 추정한 를 바탕으로, 업데이트
위 2, 3번 과정을 반복하면서 원하는 지점에 도달할 때까지 진행하는 방법을 Gaussian Mixture Model이라고 한다.
k-means도 유사하게 2, 3번 과정을 반복하는데, 평균만을 업데이트한다.