13 Matrix Factorization by Optimization
GPU를 활용한 병렬화가 용이하다.
13.4 Matrix Factorization Formulation
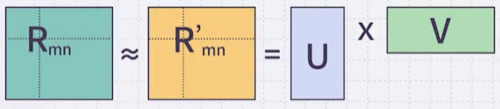
어떤 행렬 을, 두 개의 행렬 곱( )으로 근사하는 기법을 Matrix Factorization이라고 한다.
- 오차 (주로 경사 하강법으로 최적화)
오차를 최소화할 때, 일반적으로 기계 학습의 regularization 항을 추가한다.
- , 가 최대한 희소하도록 정규화
Linear Algebra로 표현하면 다음과 같다. (L2 norm)
13.4.1 Solve with Gradient Descent
경사 하강법을 사용하여 와 를 업데이트할 수 있다.
| **Algorithm** |
| *for t = 1 to infinite* { *for all m and p*, *for all p and n*, } |
13.5 Matrix Factorization Variations
기본 형태는 다음과 같다.
- R을 근사하는 , 탐색
다음은 학습 파라미터 (bias)를 포함하는 variation이다.
예를 들어, 영화 점수를 사람별로 매긴 행렬이 있다면, 사람 A행 B행 C행마다 bias가 다르게 존재해야 한다.
- 다음을 근사하는 , 탐색
- 다음을 근사하는 (평균 를 제외한) , , , 탐색
예를 들어 마지막 수식의 target function은 다음과 같다.
Notes: 미분 수식
13.5.1 Collective Matrix Factorization
다음은 주로 추천 도메인에서 사용하는 collective matrix factorization의 예시다.
- 어떤 유저가 영화를 고르는 선호도와, TV 채널을 고르는 선호도는 유사할 것이다.
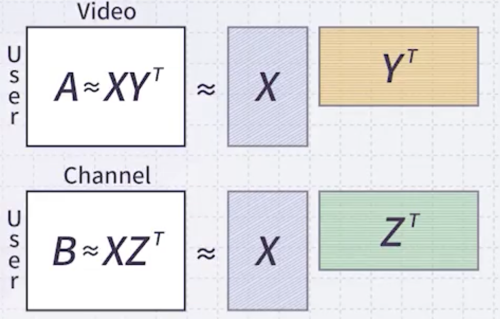
두 데이터에서, user factor 를 공유하는 조건으로 손실 함수를 modeling한다.