12 Gaussian Process
Gaussian Process는 회귀(Regression) 문제를 풀기 위한 Bayesian 기반 방법론이다.
| Kernel Regression (Non-Parametric, Non-Bayes) |
GP Regression (Non-Parametric, Bayes) |
|---|---|
 |
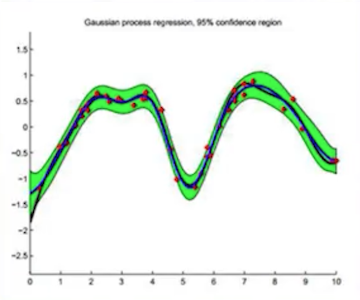 |
일반적으로 regression은 점 추정(unknown x에 대한 y 값이 무엇일까?)이다. 그런데 GP는 점 추정이 아닌 구간 추정(y가 취할 수 있는 값의 확률 분포)에 해당하는 개념이다.
함수의 분포를 알기 때문에, 예측 값의 confidence를 구할 수 있다.
12.1 Gaussian Distribution
Gaussian Distribution(정규 분포)을 복습해 보자.
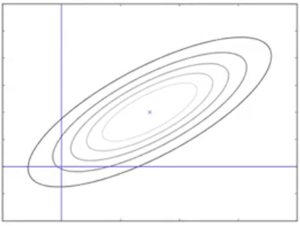
평균 값에서 거리가 멀어질수록 확률이 줄고, 이에 대한 분산( 공분산 행렬 )이 존재한다. Gaussian distribution의 확률 밀도 함수(PDF)는 다음과 같다.
Notes: Covariance
공분산은 두 개의 축(변수) X, Y 사이의 관계를 나타내는 척도로, XY의 평균 - X의 평균 * Y의 평균으로 정의한다.
이렇게 모든 축에 대한 공분산을 행렬로 묶은 것이 covariance matrix(공분산 행렬)이다.
- 이며, 과 같이 대칭 행렬이다.
(첫 번째 축, 첫 번째 축), (첫 번째 축, 두 번째 축), ..., (첫 번째 축, k번째 축) 이후 (두 번째 축, 첫 번째 축), (두 번째 축, 두 번째 축), ..., (두 번째 축, k번째 축), ...
12.1.1 Covariance Matrix
다음은 다양한 모양의 공분산 행렬을 나타낸 예시다.
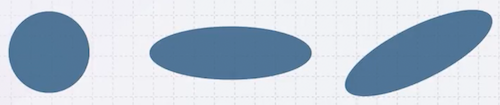
- 원 모양(diagonal)
- 타원 모양(diagonal)
- 회전한 타원 모양
이때 공분산은 correlation과 관련이 있지만, 언제나 관계가 성립하지는 않는다. ('normalized covariance가 correlation이다'로 기억하자.)
다음은 두 축을 갖는 Gaussian distribution 예시다. 평균과 공분산 행렬은 다음과 같다.
이러한 분포를 바탕으로 구간 추정, 즉 regression과 유사한 작업이 가능하다.
- 예를 들면, 가 a라는 값을 가질 때, 는 어떤 값을 가질지 예측할 수 있다.
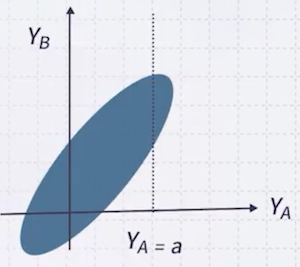
파란색: 가 존재할 수 있는 구간 (단, 확률적인 구간이기 때문에 바깥에 점이 있을 수도 있다)
이처럼 주어진 Gaussian distribution이 있을 때 값을 알고 있다면, 는 Gaussian distribution이다.
12.2 Gaussian Process
어떠한 함수 가 있지만 해당 함수를 모른다고 하자. 이때 일 때 , 일 때 , 일 때 은 관측하였다.
linear regression와 같은 다양한 회귀 기법을 통해 함수를 추정할 수 있다. 지금은 Gaussian Process(GP)를 통해 함수를 추정해 볼 것이다.
GP 추정을 위해 다음을 먼저 가정해야 한다.
-
가 Gaussian distribution을 따른다.
-
평균과 공분산 행렬을 안다.
-
평균: 일반적으로 0으로 가정( 의 평균도 0, 의 평균도 0, 의 평균도 0, 의 평균도 0 )
-
공분산: 과 가 가까워질수록 과 공분산은 커지고, 멀어질수록 작아진다고 가정
(위 가정에 부합하는 함수를 정의하여 공분산으로 사용한다.)
값이 random variable이며 임의의 모든 값을 가지므로, 평균을 0으로 가정하는 것은 타당하다.
12.2.1 Example 1
일 때,
를 추정해야 한다.
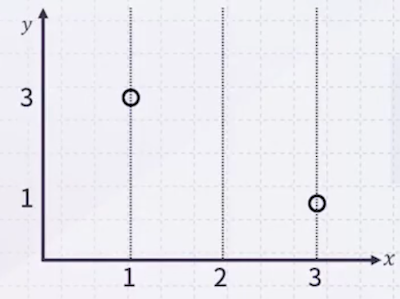
이를 로 두고 를 추정할 것이다. 평균과 공분산 행렬은 다음과 같다.
구하고 싶은 값은 이다.
즉, 평균으로 약 1.4를 갖는 Gaussian 함수로 추정한 것이다.
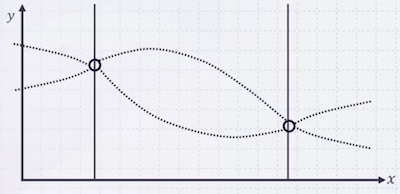
12.2.2 Example 2
더 많은 지점의 값을 알수록 를 보다 잘 추정할 수 있다.
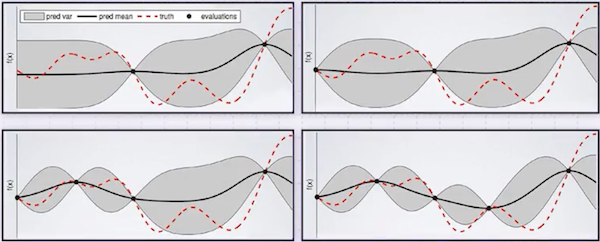
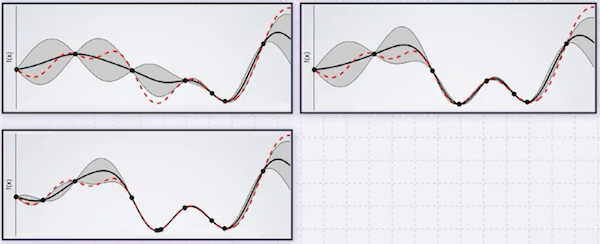
빨간색: 원래 함수, 검은 점: 관측한 값, 회색 영역: GP가 추정한 함수가 존재할 수 있는 범위
주의해야 할 점은 covariance 함수로, 해당 함수가 바뀌면 추정하는 함수도 달라지게 된다. (사용자가 잘 선택해야 한다.)
12.3 Summary
GP는 joint Gaussian distribution으로 정의되며, 이 Gaussian distribution을 따른다고 가정한다.
-
Given Training Data
-
Test Data
이때 평균이 0이며 분산에 대한 함수는 kernel 로 주어진다고 하면, Posterior Gaussian Process를 정의할 수 있다.
- Assumption
- Posterior GP