9 Support Vector Machine(2)
다음 세 가지 데이터 분포를 살펴보자.
| Example | Linearly Separable? |
|---|---|
 |
Yes |
 |
Yes(considering error) |
 |
No |
세 번째 예시는 linear 경계로 나눌 수 없다. 이럴 때는 non-linear 경계가 필요하며, 이를 위해서는 먼저 데이터를 고차원으로 매핑해야 한다.
9.1 Non-Linear SVM
다음은 1차원 점을 2차원으로 매핑한 예시다.
 |
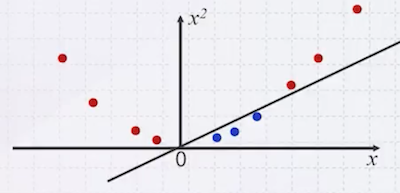 |
이렇게 찾은 경계를 다시 원래 1차원으로 보내면 곡선 형태가 된다.
매핑 함수는 직접 다양하게 정의할 수 있다.
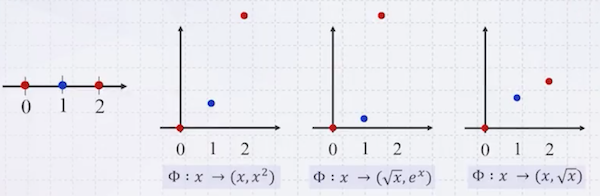
이때 얼마나 고차원으로 매핑해야 하는가에 대한 답은 수학적으로 증명되어 있다.
- 개의 점이 있다면, 차원으로 매핑 시 무조건 직선 경계로 나눌 수 있다.
여기서 은 worst case에 해당한다.
9.1.1 Non-Linear SVM: Formulation
앞서 Non-Linear SVM을 수식으로 표현해 보자.
-
given where
-
mapping function
이렇게 고차원으로 확장한 데이터를 대상으로 Linear SVM 수식을 적용한다.
수식에 대한 해는 다음과 같다.
9.1.2 Example
다음 예시에 대해 Non-Linear SVM을 적용해 보자.
위 데이터를 고차원으로 매핑하면 다음과 같다.
문제는 argmax 수식에서 내적에 해당하는 계산이다. 차원이 커질수록 내적에 필요한 계산량이 급격히 증가한다.
예를 들어 1만 개 데이터셋 쌍에 대해 1만 차원으로 확장한다고 가정하면, 10000 * 10000 쌍에 대한 내적으로 1조 번의 곱셈 연산이 필요하다.
9.2 Kernel Trick
Non-Linear SVM의 목표는 엄밀하게는, (mapping 자체가 아닌) mapping 후의 내적 값이다. 다음 예시를 보자.
둘을 내적하면 다음과 같다.
변환 후의 내적 값을 보면, 변환 식은 보이지 않고 원래의 벡터 데이터만 남는다. 즉, 고차원으로 보내는 수식만 잘 정의하면, 내적 값을 바로 구할 수 있다. 이를 Kernel Trick 이라고 한다.
이미 잘 알려진 커널 함수가 많이 존재한다.
9.2.1 Definition of Kernel
고차원으로 확장한 두 feature vector의 내적에 대응하는 함수 를 kernel이라고 한다.
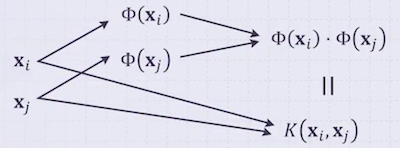
kernel 개념은 사용한 대표적인 기법은 SVM이 있으며, 이러한 기법들을 kernel machine이라고 부른다.
9.2.2 Final Formulation of SVM
다음이 kernel trick을 적용한 SVM 수식이다.
해는 다음과 같다.
(Prediction) unknown x를 다음과 같이 예측할 수 있다. ( 일 때 +1, 그렇지 않으면 -1 )
9.2.3 Some More on Kernels
대표적인 kernel 5개를 살펴보자. (Linear, Gaussian이 가장 많이 사용된다.)
| Kernel | Formula |
|---|---|
| Linear Kernel | |
| Homogeneous Polynomial Kernel | |
| Polynomial Kernel | |
| Gaussian (RBF) Kernel | |
| Sigmoid Kernel |
: 직접 정의
조금 더 세부적으로 살펴보자.
- Homogeneous Polynomial Kernel
- RBF Kernel
일반적으로 RBF 커널을 많이 사용하는 이유는, 데이터를 모두 무한 차원으로 매핑한 뒤, 무한 차원에서 직선 경계를 찾기 때문이다.
9.3 Summary
다음은 SVM의 장단점을 요약한 내용이다.
-
장점
-
최적의 separating hyperplane을 찾는다.
-
고차원 데이터 처리에 유리하다.
-
일반적으로 잘 작동한다.
-
단점
-
positive negative, multi-class 적용이 불가하다. (binary classification만 가능)
-
좋은 커널 함수를 사용해야 한다.
-
메모리 사용량 및 지연시간(CPU) 비용이 크다.
-
QP(Quadratic Problem)에서의 Lagrange multiplier: 수치 안정성 문제가 발생할 수 있다.