4 Hidden Markov Model(1)
Hidden Markov Model은 sequence processing을 위한 확률 모델이다.
e.g., Sentimental analysis: 예를 들어, 리뷰 문장이 긍정적인지 부정적인지 판단하는 문제
4.1 Markov Models
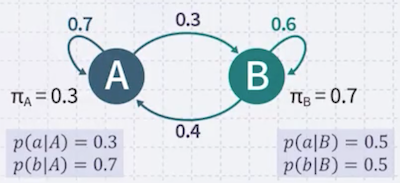
Markov Model은 final state machine이다. 예를 들어, A와 B state가 있으며 state의 transition이 존재한다.
| 예시 | 특정 state에서 시작할 확률 | 랜덤하게 state가 변화할 확률 |
|---|---|---|
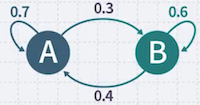 |
|
|
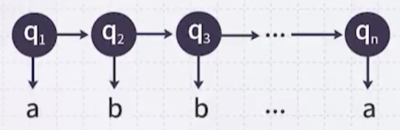
예를 들어, 다음 예시는 A, B, C state에서 계속 변화하면서 생성된 sequence이다.
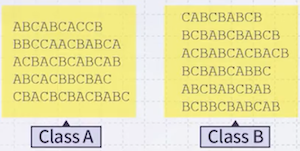
다음 예시에서 AABBABAB 문장이 생성될 확률을 구해보자.
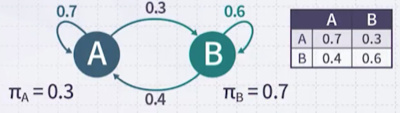
앞서 확률 계산을 수식으로 일반화하면 다음과 같다.
AABBABAB에서, 가장 높은 확률의 다음 상태는?: B(0.6)
4.1.1 Markov Models: Some Questions
반대로 특정 state로 시작할 확률을 몰라도, 이미 생성된 문자열을 토대로 추론할 수 있다.
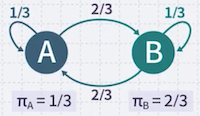
- 관찰: ABBBABA, BABBAAB, BABA, AB, BAA, BBAA
(1) 6개 문장 중에서, A로 시작한 문장은 2개, B로 시작한 문장은 4개이다.
(2) A에서 A로 간 개수, A에서 B로 간 개수를 센다.
e.g., ABBBABA:
ABBBABA 두 번
(3) B에서 A로 간 개수, B에서 B로 간 개수를 센다.
4.2 Hidden Markov Models
Hidden Markov Model(HMM)은 기계의 state를 관찰할 수 없다는 가정으로 시작한다. 즉, 지금 기계가 A state인지 B state인지 알 수 없다.
대신, 출력을 관찰할 수 있다. 만약 기계가 소문자 a를 출력했다면 state는 무엇일까?
-
state일 경우: 0.3의 확률 ( )
-
state일 경우: 0.5의 확률 ( )
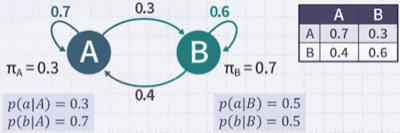
이처럼 라는 state는 관찰할 수 없으며, 대신 확률적으로 출력되는 a, b만을 관찰할 수 있다.
앞서 예시에서 abababab를 출력할 확률을 구하면 다음과 같다. (상수를 계속 곱하면 된다.)
반대로 출력이 주어졌을 때(given) 역시, state transition 확률을 추정할 수 있다.
4.2.1 Formal Definition
일반적으로 HMM은 세 가지 파라미터를 포함한 식으로 정의한다.
-
: transition 확률 (transition probability)
-
: 각 state에서 어떤 출력을 생성할지 확률 (output probability)
-
: 처음 어떤 state로 시작할지 확률 (initial probability)
State = , output =
4.2.2 Three Basic Problems for HMM
HMM에서 주로 계산하는 세 가지 문제는 다음과 같다.
-
(1) 출력 문장 와 가 주어졌을 때,
-
(2) 출력 문장 가 주어졌을 때, 가장 높은 확률로 문장을 출력할 (maximize )
-
(3) 출력 문장 와 가 주어졌을 때, 문장 생성 과정에서의 state sequence 추론
4.3 Problem 1
문제: 출력 문장 와 가 주어졌을 때, 가 출력 문장을 생성할 확률 ?
먼저 HMM 내부에서 state transition에 주목한다.
(1) 예를 들어 ababab가 출력 문장이라고 하면, state 에서 (a) 가 나올 확률, 에서 (b) 가 나올 확률, ... 을 곱하면 된다.
(2) state가 에서 로 transition할 확률, 에서 로 transition할 확률, ... 을 곱하면 된다.
앞서 두 계산을 합치면 다음 수식으로 정리할 수 있다.
그러나, 의 개수에 주의해야 한다. 가능한 state transition 개수 이 얼마나 큰가에 따라, 연산이 지수적으로 증가한다.
-
#possible sequences = ( 출력 문장 길이 )
-
forward-backward procedure를 사용하면 효율적으로 계산할 수 있다.
예를 들어, 문장 길이가 10이며 가능한 state가 A, B로 2라면, 2^10 = 1024개 항을 모두 더해야 한다.
4.3.1 Forward Procedure
Dynamic Programming으로 확률을 구해가는 과정이 필요하다.
앞서 ababab를 출력했고 state는 A, B를 가졌다.
먼저, 마지막 b를 출력한 state가 A라고 가정하고, 해당 가정의 확률을 구해보자.
이후 B인 경우의 확률도 구해서 더하면 된다.
- 다섯 번째 B state에서 A로 갈 확률 * 다섯 번째 A state에서 A로 갈 확률
각 항을 변환하면 다음과 같다.
- 여기서 번째 state가 일 확률을 로 치환하면 다음과 같다.
전체 식을 정리하면 다음과 같다.
요약하자면, 일 때 ababab 확률과 일 때 ababab 확률을 더해주면 된다.
일반화한 수식은 다음과 같다.
- : state
forward variable
(1) Initialization
(2) Induction
(3) Termination
4.3.2 Backward Procedure
3단계 절차는 다음과 같다.
(1) Initialization
(2) Induction
(3) Termination
4.3.3 Combination of Forward and Backward
앞서 두 procedure를 결합할 수 있다.
정리하면 다음과 같다.