14 Vision Transformer
EfficientML.ai Lecture 14 - Vision Transformer (MIT 6.5940, Fall 2023, Zoom)
14.1 Vision Transformer
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 논문(2020)
Vision Transformer(ViT)는 2D image를 패치 단위로 나눈 token을 입력으로 한다.
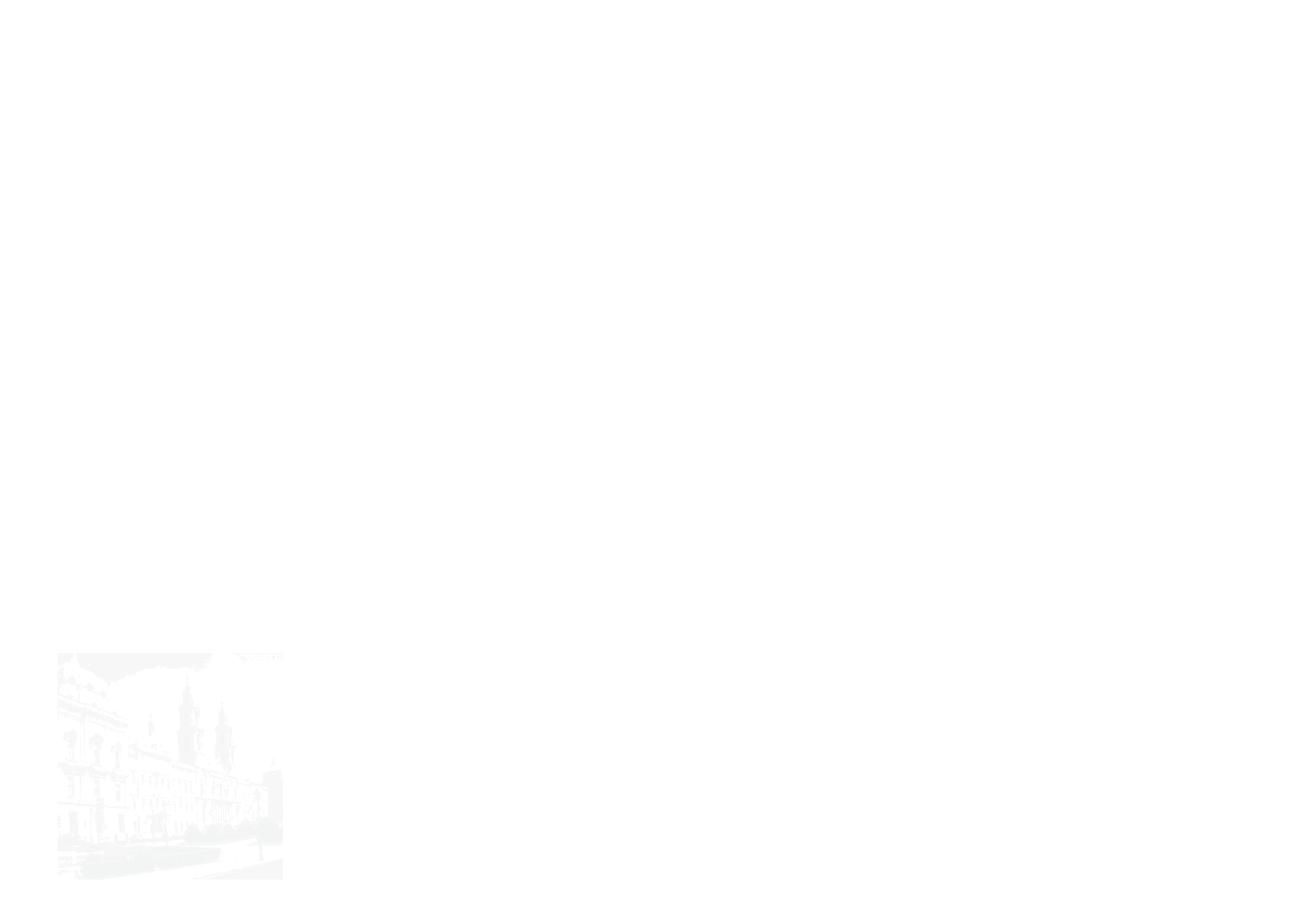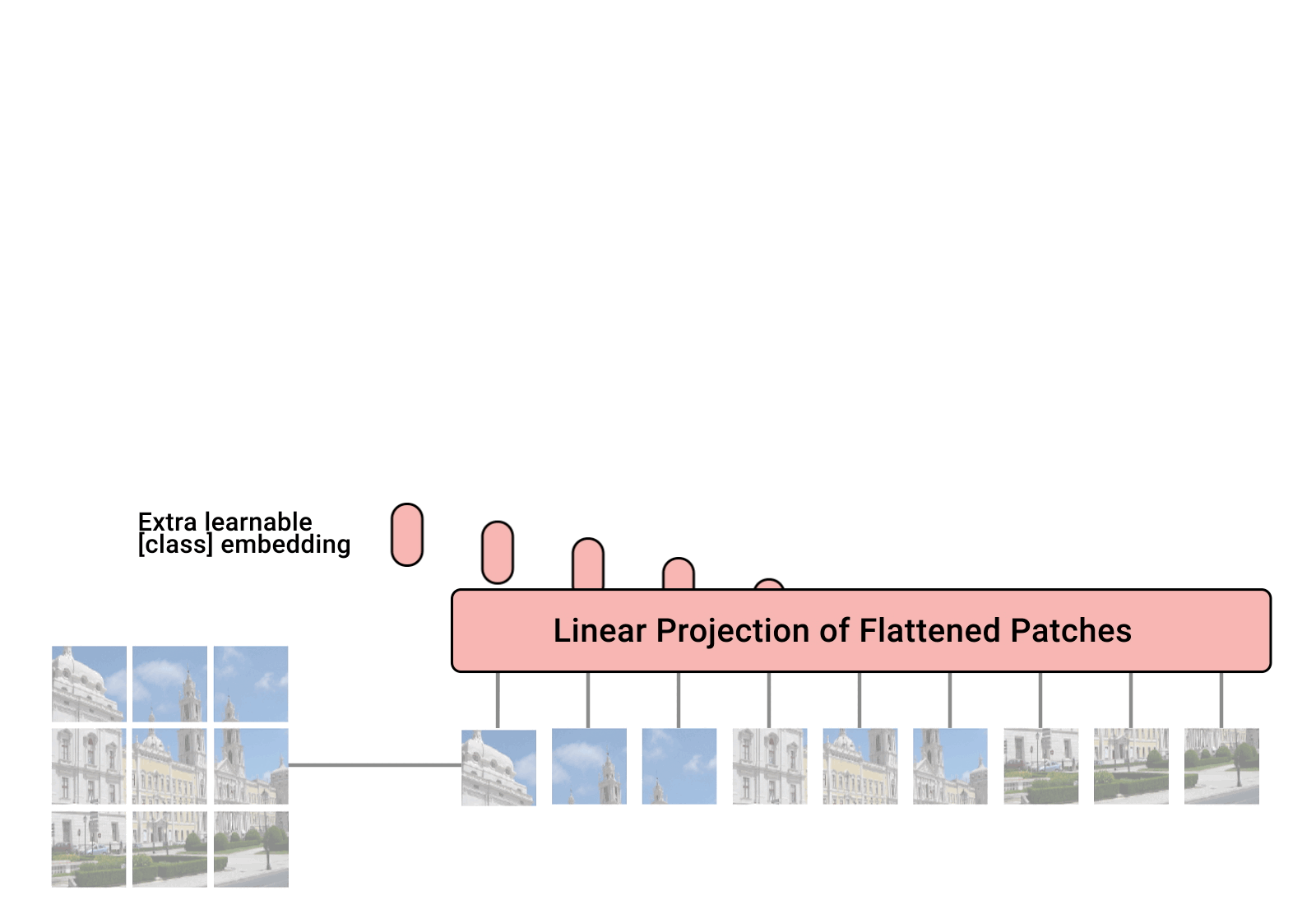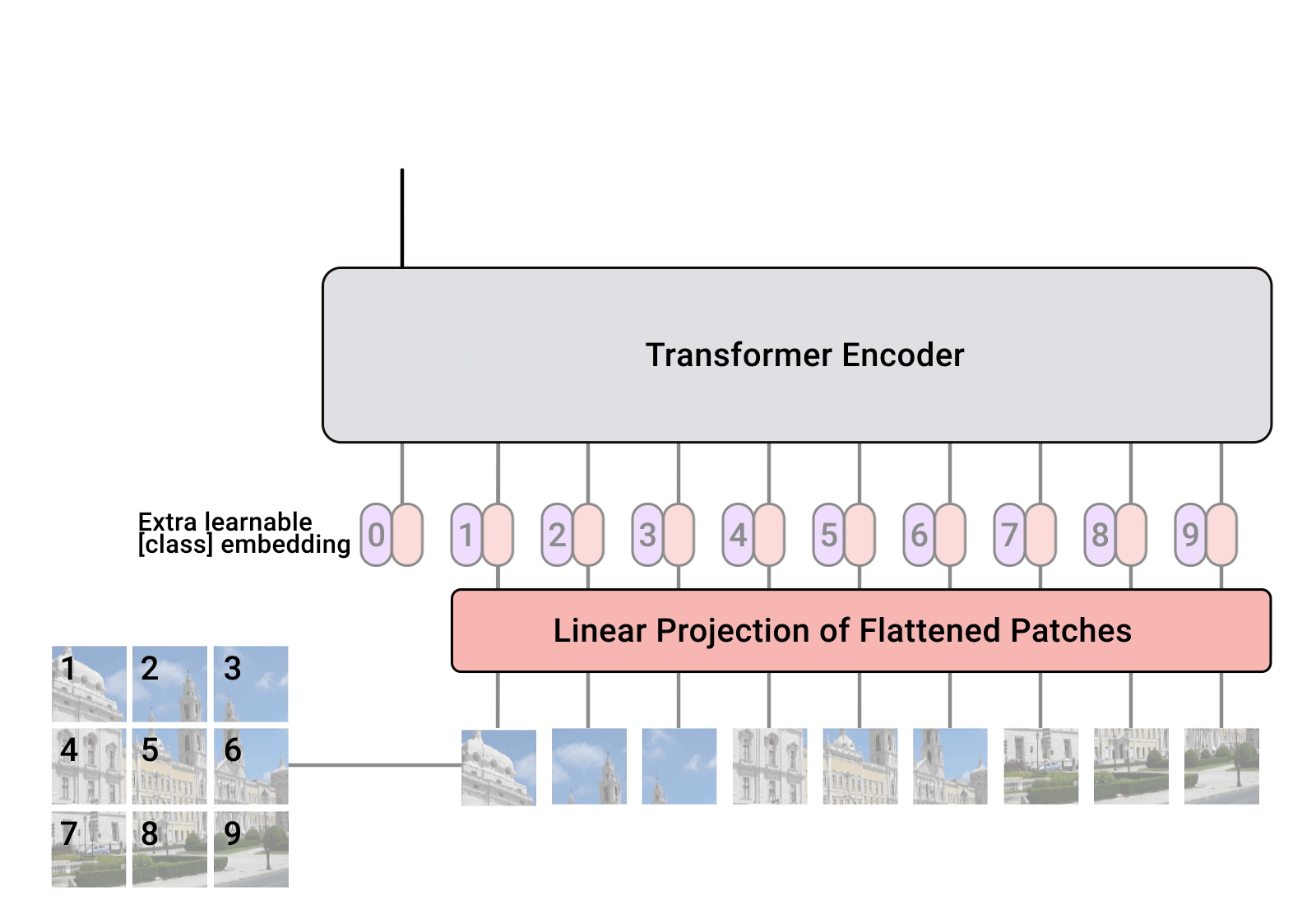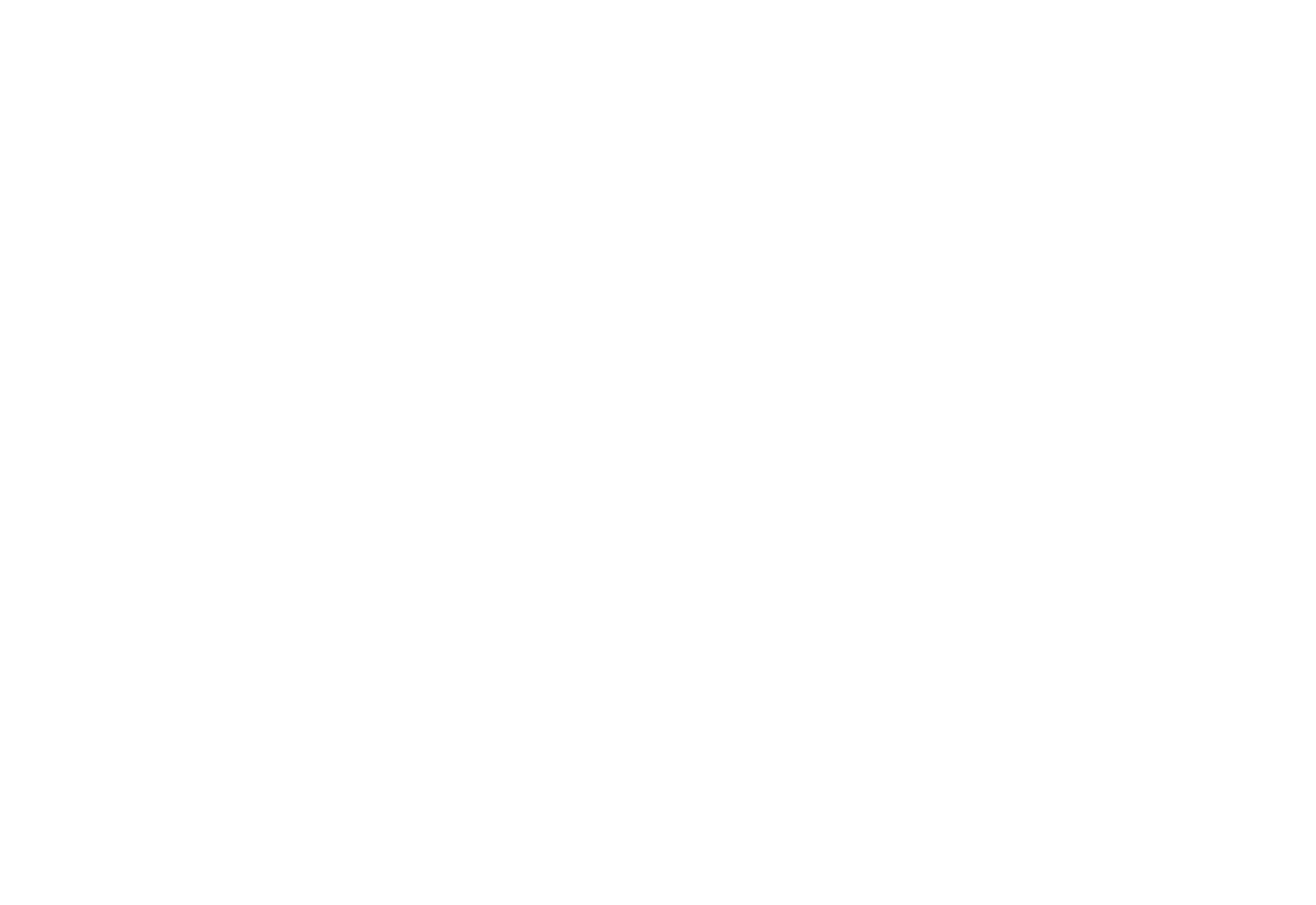
- tokenization
| 2D Image | Tokenization | |
|---|---|---|
 |
 |
|
| size: 96x96 patch size: 32x32 |
#tokens: 3x3=9 dim of each token: 3x32x32=3,072 |
- linear projection: 주로 convolution 활용 (서로 다른 패치에 대해 하나의 동일한 convolution)
 |
 |
|---|---|
| input dim = 3,072 output dim(hidden size of ViT) = 768 |
#Parameters: 3,072x768 = 2.36M |
현재 예시: "32x32 Filter, stride 32, padding 0, in_channel=3, output_channel = 768" convolution 레이어를 사용한다.
14.1.1 Model Variants
논문에서는 세 가지 ViT 모델군을 제안하였다. (Patch size: 2, 4, 8, 16, 32)

(notation) ViT-L/16 = ViT-Large, 16x16 패치 사용
다음은 ImageNet 정확도를 비교한 도표다, 많은 양의 데이터(JFT-300M)로 사전학습한 경우, ResNet보다 우수한 정확도를 달성하였다.
(notation) ViT-b: ViT-Base에서 hidden dimension을 절반으로 줄인 모델
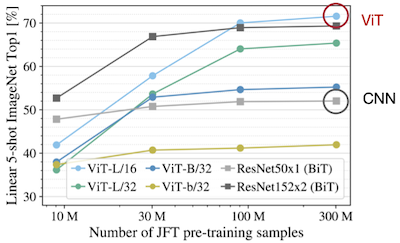
14.2 Challenge: High-Resolution Dense Prediction
dense prediction: 이미지 내 각 픽셀이 어느 클래스인지 예측
Computer Vision에서는 고해상도 입력이 필요한 다양한 도메인이 존재한다. (저해상도: 작은 물체와 같은 세부 정보를 인식하기 어렵다.)
| low-res | high-res |
|---|---|
 |
 |
| Medical Image Segmentation | Super-Resolution (SR) |
|---|---|
 |
 |
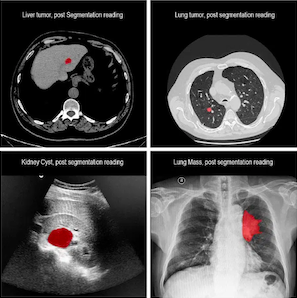
하지만, ViT는 고해상도에서 연산량이 폭발적으로 증가한다. (해상도 증가 연산량 quadratic 증가)
14.2.1 Applications: Segment Anything
SAM 2: Segment Anything in Images and Videos 논문(2024): streaming memory 메커니즘을 도입하여 프레임 단위로 동영상 처리
SAM 3: Segment Anything with Concepts 논문(2025): 특정 개념(concept) 프롬프트 전달 시, 관련 객체를 한번에 검출하고 ID 부여
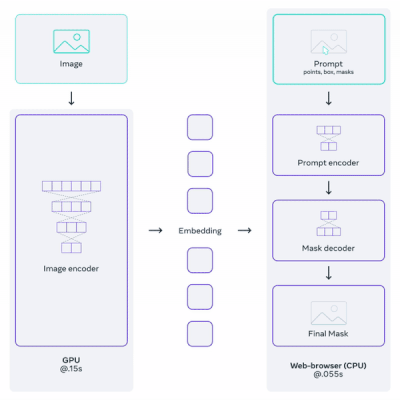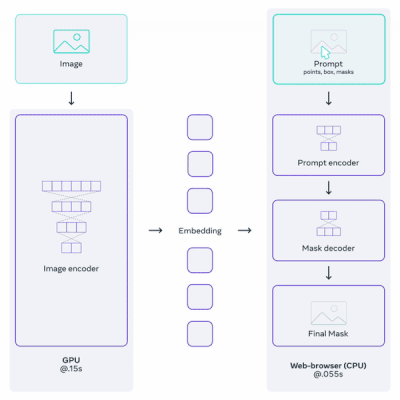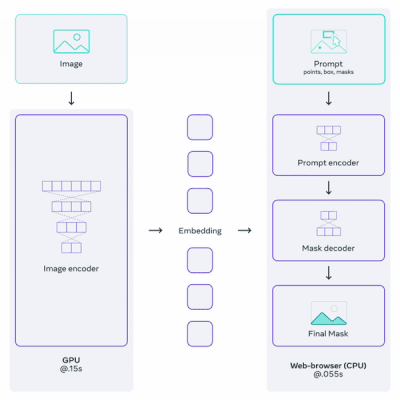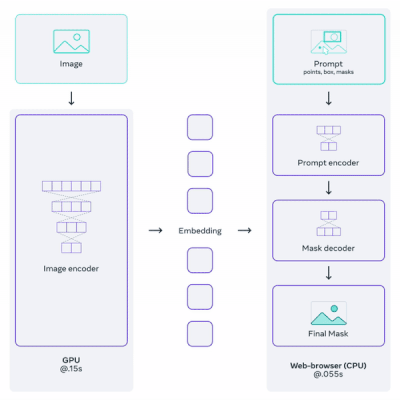
Segment Anything은 이미지 인코더로 ViT를 채택한 image segmentation(이미지 분할) 모델이다.
| Inference | Example |
|---|---|
 |
 |
SAM 2: streaming memory 메커니즘을 도입하여, 프레임 단위로 동영상을 처리할 수 있다. (SA-V 데이터셋 학습, Hiera 이미지 인코더 활용)
자체적으로 구성한 SA-1B 데이터셋으로 학습: 11M high-res image, 1B 개 이상의 segmentation mask
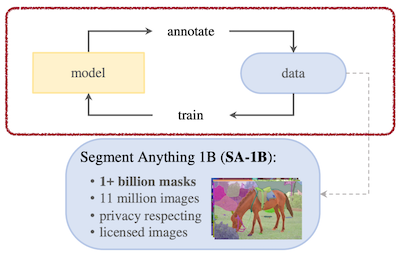
14.2.1.1 SAM Architecture
On Efficient Variants of Segment Anything Model: A Survey 논문(2024)
Avishek Biswas, Segment Anything 2: What Is the Secret Sauce? (A Deep Learner’s Guide)
백본은 크게 3가지 요소로 구성되며, 지원하는 다양한 타입의 프롬프트(e.g., points, boxes, masks, text)에 따라서 이미지를 분할한다.
-
Image Encoder: MAE(Masked Autoencoder) pre-trained ViT
-
Prompt Encoder: sparse(points, boxes, text), dense(masks) 프롬프트 임베딩
-
Mask Decoder: 임베딩(image, prompt)에서 segmentation mask 예측
| Component | Description |
|---|---|
| SAM 1 | 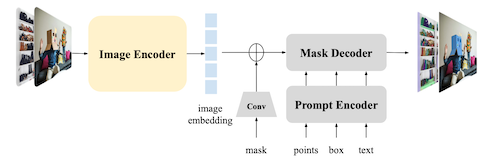 |
| Mask Decoder | 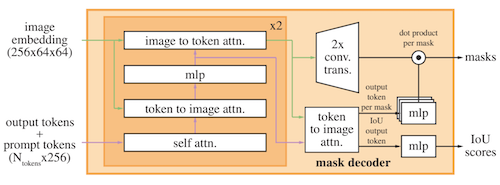 |
이때 Mask Decoder는 멀티모달 feature fusion을 위한 cross-attention 메커니즘을 사용한다. (segmentation mask, IoU 계산에서 활용)
SAM 2 Mask Decoder 추가 계산: occlusion score(프레임 내 query 객체 존재 여부), object pointer(mask token을 MLP로 벡터화)
Notes: SAM 2 Architecture
Memory Encoder: 출력 마스크를 Bank에 저장 (conv downsampling 이미지 인코더 임베딩과 합산하여 저장)
Memory Bank: (1) 최근 개 출력 마스크, (2) 개 프롬프트 임베딩, (3) object pointer 배열 저장
Memory Attention: 이미지 인코더 임베딩에 self-attention 과거 메모리 뱅크 정보와 cross-attention
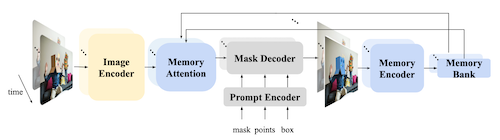
14.3 Efficient Attention
SAM 사례에서 ViT(image encoder)는 파라미터 크기의 대부분을 차지(90% 이상)하며, 고해상도 입력에서 매우 큰 연산량을 요구한다.
- 따라서, 보다 경량화한 아키텍처나 효율적인 attention 메커니즘이 필요하다.
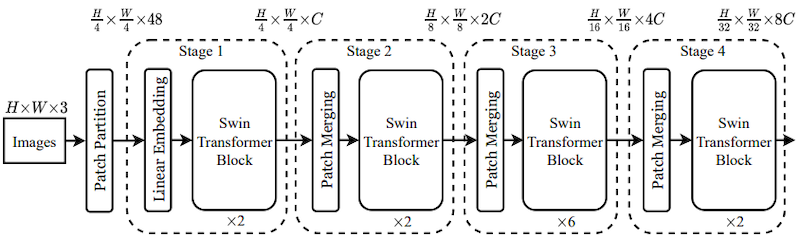
14.3.1 Swin Transformer: Window Attention
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows 논문(2021)
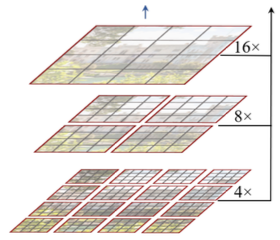
Swin Transformer은 연산량을 최소화할 수 있는, local window 단위의 window attention을 제안하였다. (연산 복잡도: linear하게 증가)
| Original Attention | Window Attention |
|---|---|
 |
 |
| all token 대상 연산 | local window만 연산 |
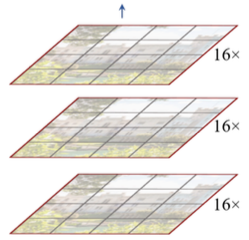
Notes: feature map 크기는 레이어를 거치며 점차 감소한다.
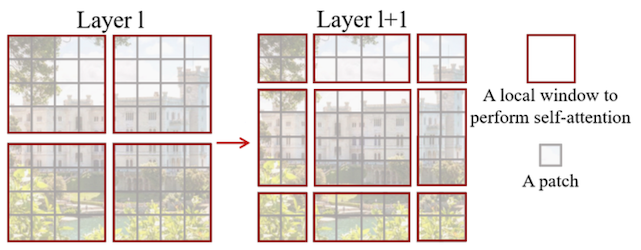
이때 window 간의 정보 교환을 위한 shifted window 블록을 포함한다. (예시: 2 pixel shift)
| Shifted Window Partition | Two Successive Block |
|---|---|
 |
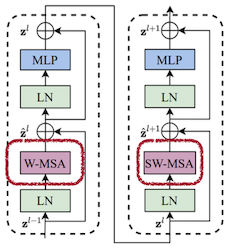 |
SW: Shift Window, MSA: Multi-head Self-Attention
14.3.2 FlatFormer: Flattened Window Attention
FlatFormer: Flattened Window Attention for Efficient Point Cloud Transformer 논문(2023)
FlatFormer는 희소도를 활용한 Flattened Window Attention(FWA) 설계를 제안하였다.
-
(1) padding이 필요한 동일한 윈도우(Equal-Window) 대신, 동일한 크기(Equal-Size)로 그룹
-
(2) 그룹별 self-attention(여러 axis로 수행) 및 shifted window attention 적용
| Equal-Window | Equal-Size | |
|---|---|---|
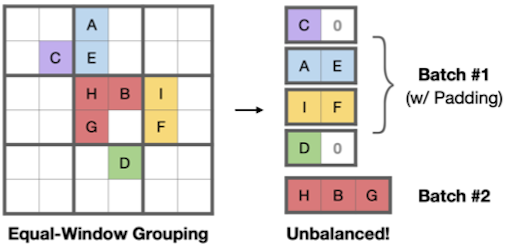 |
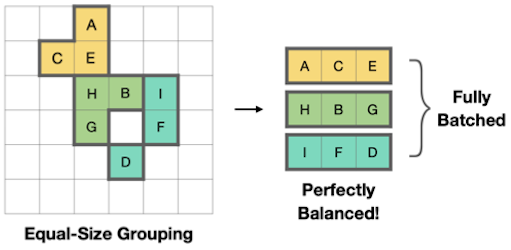 |
|
| (+) | spatial proximity | balanced computation workload |
| (-) | computational regularity | geometric locality |
다음은 Jetson AGX Orin 보드에서 획득한 벤치마크로, 타 모델 대비 우수한 FPS(Frames Per Second)를 달성하였다.
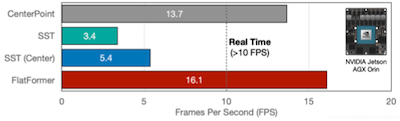
Notes: 3D Point Cloud 데이터는 일반적으로 99% 수준의 희소도를 가진다.

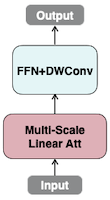
14.4 EfficientViT: Linear Attention
EfficientViT: Multi-Scale Linear Attention for High-Resolution Dense Prediction 논문(2022)
EfficientViT은 ReLU 기반 linear attention으로 similarity 계산을 단순화한다. (연산 비용: 으로 감소)
| Softmax Attention | Linear Attention | |||
|  | vs |  |
**(ab)c = a(bc)** (associative property of Matmul) |
 |
| Cost: | Cost: | Cost: | ||
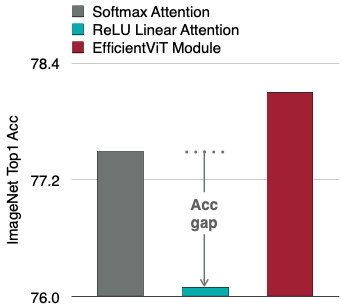
그러나, linear attention은 local information을 포착하기 어려운 문제를 가진다.
| Attention Feature Map | Accuracy Gap |
|---|---|
 |
 |
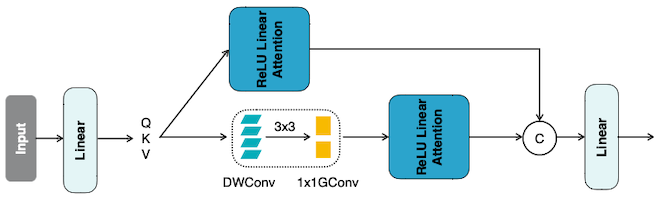
14.4.1 EfficientViT Module: Multi-Scale Aggregation
따라서, 논문에서는 depthwise convolution(DWConv) 분기를 추가하는 설계로 local information을 강화하였다.
| Aggregate multi-scale Q/K/V tokens | EfficientViT Module |
|---|---|
 |
 |
해당 설계로 정확도 손실을 회복할 뿐만 아니라, 기존 softmax attention보다 우수한 성능을 달성하였다.
14.4.2 EfficientViT-SAM
EfficientViT-SAM: Accelerated Segment Anything Model Without Accuracy Loss 논문(2024)
후속 논문에서는 Segment Anything Model(SAM)의 image encoder를 수정한 EfficientViT-SAM 설계를 제안하였다.
prompt encoder, mask decoder: 그대로 유지
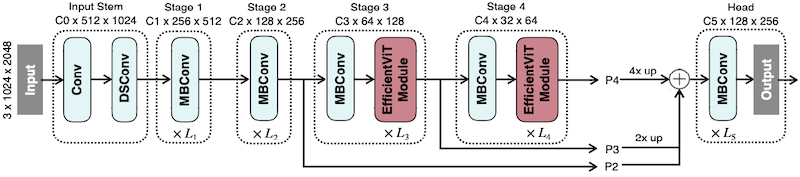
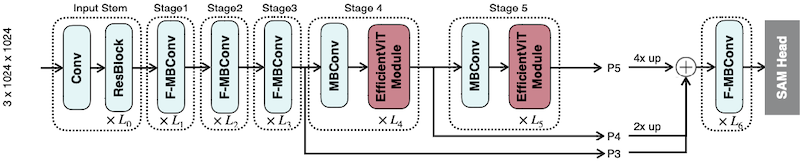
다음은 EfficientViT 및 EfficientViT-SAM 구조를 나타낸다.
-
전반부
Conv block/ 후반부 2 stage에서EfficientViT Module사용 -
후반부 3 stage에서 fused feature 획득 (
upsampling,addition)
| EfficientViT |
|---|
 |
| EfficientViT-SAM-XL |
 |
EfficientViT-SAM 학습은 2단계로 수행된다.
(1) image encoder 학습 (교사 모델: 기존 image encoder)
(2) end-to-end EfficientViT-SAM 학습 (dataset: SA-1B, 2 epochs)
14.4.3 EfficientViT-SAM: Results
다음은 세 가지 모드에서 EfficientViT-SAM가 획득한 결과다. (ViT-Huge: SAM-ViT-H)
- 기존 SAM과 비교하여 17-69배 가속을 달성하였다. (단일 NVIDIA A100 기준)
| Mode | Segmentation Results |
|---|---|
| Point |  |
| Box |  |
| Everything |  |
참고: YOLOv8, Grounding DINO를 활용한 Instance Segmentation에서도, SAM-ViT-H 대비 우수한 성능 달성
14.5 SparseViT: Sparse Attention
SparseViT: Revisiting Activation Sparsity for Efficient High-Resolution Vision Transformer 논문(2023)
sparse, high resolution 입력과 dense, low resolution 입력 중 어느 쪽이 더 자원 효율적일까?
| Uniform Resizing | Activation Pruning |
|---|---|
 |
 |
| Low Resolution (0.5x) Dense Pixels (100%) |
High Resolution (1x) Sparse Pixels (25%) |
SparseViT는 sparse, high resolution 입력이 포함하는 풍부한 정보에 주목하고, 연산량을 줄이기 위한 activation pruning 기법을 제안하였다.
Swin block(Swin Transformer)을 수정하여 사용한다.
- Step 1: Window Attention Pruning (with Non-Uniform Sparsity)
input activation을 magnitude 기준으로 희소화한다. (top-k 보존 후 정렬, 이어서 window attention)
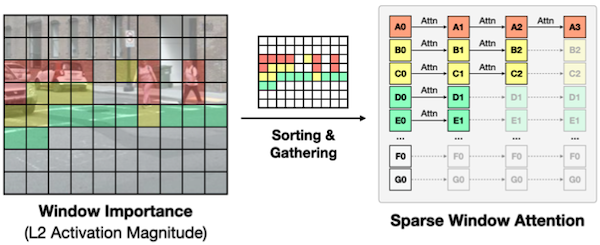
- Step 2: Sparsity-Aware Adaptation
여러 iteration 동안 각 레이어를 임의의 희소도 비율로 미세조정한다. (레이어별 민감도 조사)

- Step 3: Resource-Constrained Search
진화 알고리즘(Evolutionary Algorithm)으로, 지연시간 제약 조건에서 레이어별 최적 희소도 설정을 탐색한다.