10 Knowledge Distillation
Lecture 10 - Knowledge Distillation | MIT 6.S965
EfficientML.ai Lecture 9 - Knowledge Distillation (MIT 6.5940, Fall 2023, Zoom)
10.5 KD for Object Detection
Object Detection 도메인에서는, 크게 두 가지 문제를 추가로 해결해야 한다.
-
foreground, background를 잘 분리할 수 있어야 한다.
-
Bounding box를 잘 찾아야 한다.
이때, bounding box는 classification이 아니라, regression 문제에 해당된다.
10.5.1 Distillation Pipeline for Object Detection
Learning Efficient Object Detection Models with Knowledge Distillation 논문(2017)
Object Detection의 특징에 맞춰, 위 논문에서는 다음과 같은 절차를 통해 KD를 수행한다.
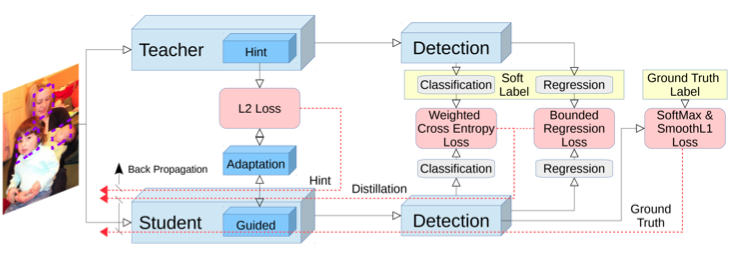
- Adaptation
교사와 학생의 intermediate feature map을 비교한다.
1x1 conv로 channel 수를 맞춘다.
- Detection head
classification, regression 결과를 모두 도출한 뒤 loss를 계산한다.
-
Weighted Cross Entropy Loss
foreground, background classification을, 서로 다른 가중치를 사용하는 것으로 class imbalance 문제를 해결한다.
-
Bounded Regression Loss
이때 margin을 두어, 학생 성능이 교사 성능 + margin 을 넘어서는 순간, loss가 0이 되며 학습이 중단되도록 구현했다.
10.5.2 Convert Regression to Classification Problem
Localization Distillation for Dense Object Detection 논문(2022)
혹은 regression 문제인 bounding box을, classification 문제로 바꿔서 KD를 수행할 수 있다.
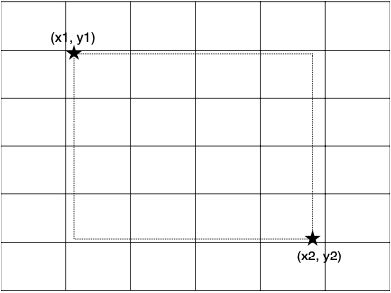
-
x축을 6개 구간으로 나누고, y축을 6개 구간으로 나눈다.
-
각 구간을 class로 지정한다.
10.6 KD for Semantic Segmentation
Structured Knowledge Distillation for Semantic Segmentation 논문(2019)
Semantic Segmentation 도메인에서는 Discriminator을 사용한 KD 방법이 제안되었다. (Adversarial Distillation)
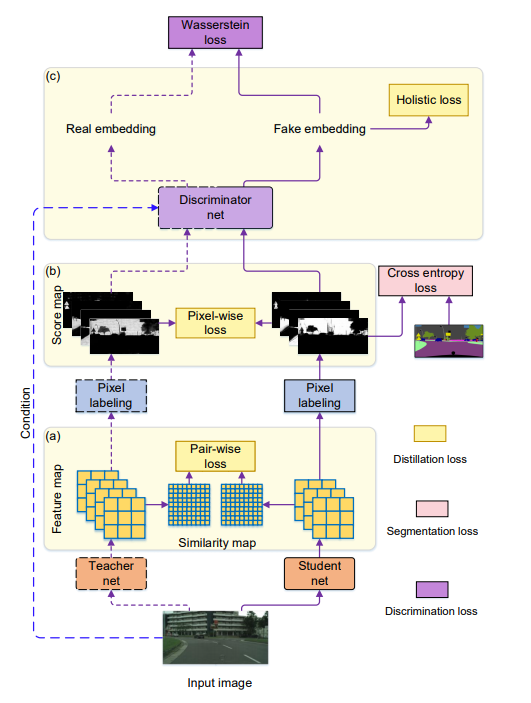
-
feature imitation: classification, detection 도메인과 유사하게 진행
-
Discriminator
adversarial loss: 학생이 discriminator를 속일 수 있도록 학습된다.
10.7 KD for GAN
GAN Compression: Efficient Architectures for Interactive Conditional GANs 논문(2020)
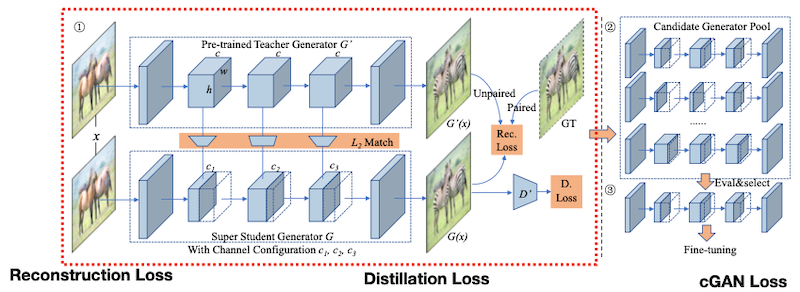
training objective는 다음과 같다.
- Reconstruction Loss
- Distillation Loss
\mathcal{L}{cGAN} = \mathbb{E}_x[\log (1- D(x, G(x)))]}[\log D(x,y)] + \mathbb{E
{\mathcal{L} }{aug} = {\mathcal{L} }(W]) $$}) + {\alpha}{\mathcal{L} }([W_{base}, W_{aug
- scaling factor : auxiliary supervision가 loss에 미치는 영향을 조절
10.9.2 NetAug Learning Curve
다음은 ImageNet 데이터셋을 이용한 학습에서 NetAug를 적용했을 때의 성능을 나타낸 그림이다.
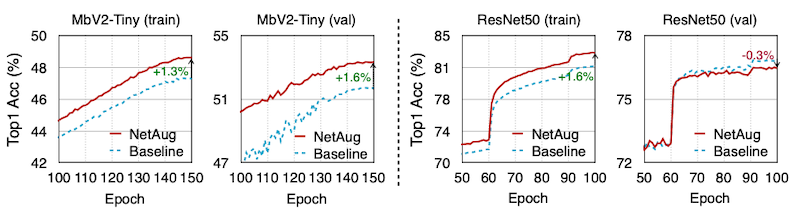
-
tiny model(MbV2-Tiny): under-fitting을 막고 성능을 향상시킨다.
-
large model(ResNet50): over-fitting을 유발한다.