Lecture 05 - Quantization (Part I)
Lecture 05 - Quantization (Part I) | MIT 6.S965
EfficientML.ai Lecture 5 - Quantization (Part I) (MIT 6.5940, Fall 2023, Zoom recording)
quantization(양자화)는 연속된 신호(입력)을 discrete set으로 변환하는 기술이다.
| Before Quantization | After Quantization |
|---|---|
 |
 |
메모리 사용량, 전력 소모, 지연시간, 하드웨어 설계(silicon area) 등 다양한 차원의 이득을 얻을 수 있다.
5.1 Numeric Data Types
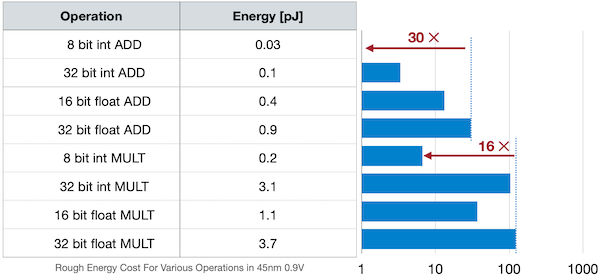
대체로 bit-width를 사용하는 연산일수록, 에너지 소모량이 적어 효율적이다.
5.1.1 Integer
다음은 십진수 49를 8 bit 정수(INT8)로 표현한 것이다.
| **Unsigned Integer** n-bit range: |  |
| **Signed Integer** (**Sign-Magnitude**) n-bit range: > |  |
| **Signed Integer** (**Two's Complement Representation**) range: > , |  |
5.1.2 Fixed-Point Number
fixed-point 표현은 정수 연산용으로 최적화된 하드웨어를 사용할 수 있다는 장점을 갖는다. 다음은 8bit fixed-point로 소수를 표현한 예시다.
핵심은 shift 연산이다. (shift right = 나누기 2, left shift = 곱하기 2)
| `fixed<8,4>`(의미: Width 8bit, Fraction 4bit) - Sign(1bit) - Integer(3bit) - Fraction(4bit) | 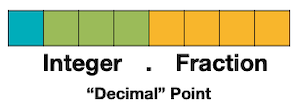 |
다음은 unsigned fixed<8,3> 예시다.
5.1.3 Floating-Point Number (IEEE FP32)
다음은 IEEE 754 스타일의 32bit floating-point를 표현한 예시다.
| Sign(1bit) Exponent(8bit) Fraction(mantissa, 23bit) |  |
Exponent Bias
e.g., IEEE FP32 0.265625 표현

5.1.3.1 Floating-Point Number: Subnormal Numbers
exponent 값이 0에 해당하는 범위를 subnormal number(비정규 값)라고 부른다.

해당 영역은 normal number과 다르게 linear하다.

| Smallest |  |
| Largest |  |
5.1.3.2 Floating-Point Number: Special Values
다음과 같은 두 가지 경우를 특수한 값으로 분류한다.
| Infinity > Normal Numbers, Exponent 0 |  |
| NaN (Not a Number) > Subnormal Numbers, Fraction 0 |  |
5.1.4 Floating-Point Number Formats for Deep Learning
fraction와 exponent를 비교하면, 딥러닝에서는 exponent width가 더 중요하다.
다음 예시를 보면, half presicion(16bit) 기준에서 exponent width를 최대한 사용하려는 의도를 엿볼 수 있다.
| Exponent (bits) |
Fraction (bits) |
Total (bits) |
|
|---|---|---|---|
 |
8 | 23 | 32 |
 |
5 | 10 | 16 |
 |
8 | 7 | 16 |
이후 NVIDIA에서는 FP8 format도 제안하였다.
| Exponent (bits) |
Fraction (bits) |
Total (bits) |
|
|---|---|---|---|
 |
4 | 3 | 8 |
 |
5 | 2 | 8 |
5.1.5 INT4 and FP4
더 나아가 INT4, FP4 포맷도 등장하였다.
| Range (Positive Numbers) |
|
|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
5.2 Uniform vs Non-uniform Quantization
: real value(원래 표현), : quantized value
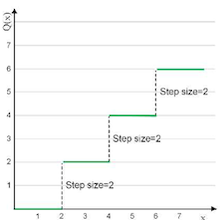
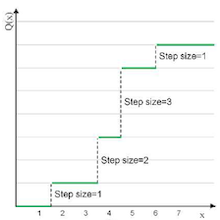
step size를 어떻게 정하는가에 따라 양자화를 분류할 수 있다.
| Uniform | Non-Uniform | Non-Uniform (Logarithmic) |
|
|---|---|---|---|
 |
 |
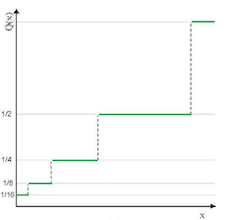 |
|
| 장점 | 동일한 step size로 구현이 쉽다 | 표현력이 우수하다. | 효율적으로 넓은 범위를 표현한다. |
-
Uniform Quantization
-
: Zero points, : Scaling factor
- Non-Uniform Quantization
- Non-Uniform Quantization: Logarithmic Quantization
5.3 Linear Quantization
대표적인 uniform quantization에 해당하는 Linear Quantization을 살펴보자.
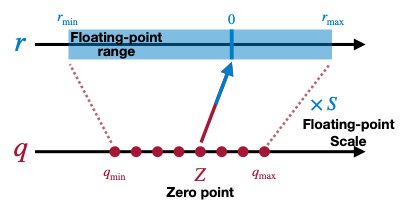
이때, floating-point range , , integer range , 는 이미 알고 있는 정보이다.
| Bit Width | ||
|---|---|---|
| 2 | -2 | 1 |
| 3 | -4 | 3 |
| 4 | -8 | 7 |
| N |
이를 바탕으로 양자화 scaling factor 및 zero point 를 구할 수 있다.
위 식은, , 두 식을 연립하여 얻을 수 있다.
5.3.1 Example: 2-bit Linear Quantization
다음의 floating point 텐서를 2-bit 양자화해보자.
(1) scaling factor
(2) zero point
Notes: 2-bit quantization
Binary Decimal 01 1 00 0 11 -1 10 -2
5.3.2 Example: Matrix Multiplication
다음은 간단한 행렬 곱셈 수식이다.
양자화를 반영하면 다음과 같다.
에 대한 식으로 정리하면 다음과 같다.
효율적으로 추론하기 위해, 가중치와 연관된 일부 항은 오프라인에서 미리 계산해 둔다.
-
: bit rescale
-
: bit addition
5.3.3 Normalization of Multiplier
위 식에서 multiplier 는 (0,1) 값을 갖는다. 따라서, fixed-point 형태로 표현하는 것도 가능하다.
-
: fixed-point multiplication
-
: bit shift
fixed-point를 사용하면, 를 정수용 하드웨어로 연산할 수 있다.
5.4 Linear Quantized Neural Network Layers
가장 간단한 예제인 symmetric linear quantization을 살펴보자. ( zero point )
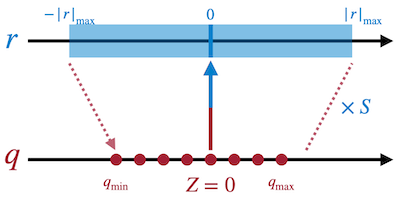
이때의 scaling factor 는 다음과 같다.
위 식은 에서 유도할 수 있다.
5.4.1 Fully-Connected Layer
이제 bias를 포함하는 fully-connected layer의 수식을 살펴보자.
차례로 수식을 정리하면 다음과 같다.
(1) ,
(2)
(3)
(4) 식으로 정리
괄호 안의 항: bit 정수 곱셈, 32 bit 정수 덧셈(overflow 방지), : bit 정수 덧셈
5.4.2 Convolution Layer
마찬가지로 convolution 연산 수식도 정리할 수 있다.
-
,
해당 수식의 연산 그래프는 다음과 같다.
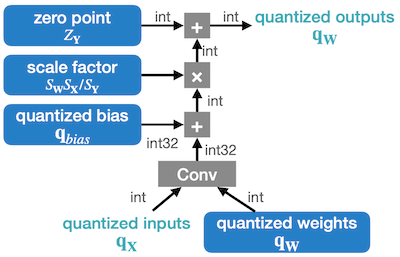
5.5 Hardware Implementation of Integer-Arithmetic-Only Inference
tinyML Talks: A Practical Guide to Neural Network Quantization
다음은 uint8 양자화 모델을 추론하는 MAC array이다.
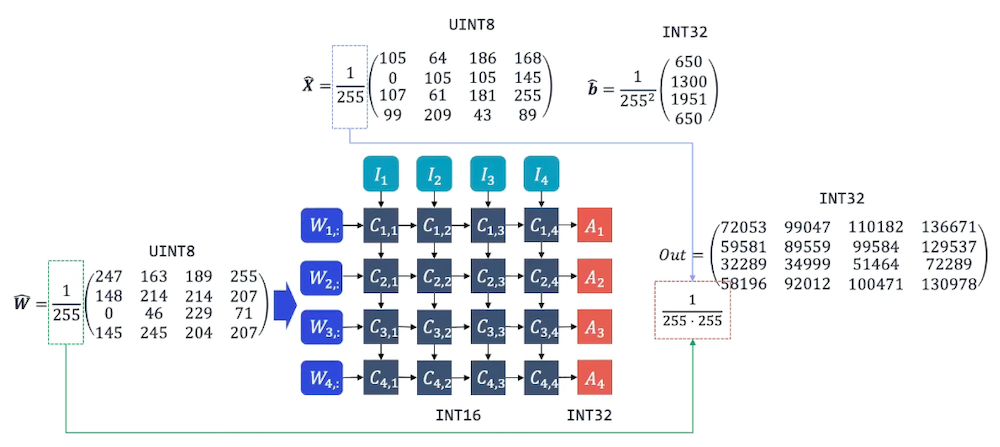
5.6 Symmetric vs Asymmetric Quantization
unsigned int 타입의 양자화는 ReLU와 유사한 output activation을 대상으로 할 때 특히 유용하다.
| Symmetric (signed) |
Symmetric (unsigned) |
Asymmetric (unsigned) |
|
|---|---|---|---|
 |
 |
 |
|
| Zero Point | |||
| INT8 Range | [-128, 127] (restricted) [-127,127] (full) |
[0, 255] | [0, 255] |
| Matrix Transform | Scale | Scale | Affine |
restricted range: full range 대비 정확도 떨어지지만, 연산 비용이 저렴하며 구현도 쉽다.
5.7 Sources of Quantization Error
linear quantization에서 양자화 오차를 발생시키는 원인을 알아보자.
 |
-
round error: 에서 근접한 값 동일한 grid
-
clip error: 범위( e.g., )를 벗어난 outlier
quantization error = round error + clip error
다음은 양자화된 값 을 로 복원한 뒤 발생한 오차를 나타낸 그림이다. scaling factor를 어떻게 정하는가에 따라, 양측 오차에서 trade-off가 발생한다.
| (case 1: round error가 큰 경우) |
|---|
 |
| (case 2: clip error가 큰 경우) |
 |
따라서, 양자화 시 최적의 절충점을 고려하여 scaling factor를 정해야 한다.